读懂天然产物系列——天然产物发现之路
发布日期:2016-06-13 17:09
来源:网络
作者:网络
浏览次数:
以下文章转载自小木虫笑玄97
天然产物的研究发现之路漫长而修远,你我求索于其中孜孜不悔;顾盼回首,我们究竟走了多远?本帖所述文章以“Dereplication”为题(直译为去重复化,引用原文释义“the discard of known compounds”即去除已知化合物),目的在于加快天然产物发现的进程。相信我们都会为这样的事情而头痛不已:耗费了大量的时间和精力,分离得到的却绝大多数都是一些已知结构(或活性)的化合物!那么毫无疑问,“Dereplication”(去除已知化合物重复的分离工作)在这里就会牢牢吸引住你我的眼球。
这是NPR上一篇综述性很强的文章,通篇围绕如何“Dereplication”,论述了1993-2014近11年里新的思路、方法和技术变革,抽丝剥茧,层层推进!说实话,撰写综述性文章的帖子是有一定难度的,因为作者观点比较分散;但在阅读过程中,我为每时每刻都能不断学习这些应用于天然产物领域的新思路和新方法而兴奋不已。因此,在这里仅对文中一些比较感兴趣的领域进行述说讨论,并真心希望通过本帖能够引起大家的交流和思考。
概述:
文章Introduction,首先从天然产物化合物的特殊性、骨架结构复杂和利于人类身心健康的优势出发,说明天然产物是药物先导化合物发现的最佳来源;进而引出天然产物发现过程中的主要 “bottleneck”或“tailback”是“Replication”,即已知结构或活性化合物的重复性获取分离。因此,在第二部分的Reviews中对相关天然产物“Dereplication”技术革新和策略、方法等方面文献进行简单梳理;第三、四部分,进行统计分析,并概括性描述了“De- replication”的发展趋势和不同技术方法。
接下来将对文章天然产物发现过程中个人比较感兴趣的“Dereplication”思路、方法和技术手段等分别论述如下:
1、HTS(高通量筛选)
依赖自动化的大规模重复性试验,完成短时间内从大量结构多样性NPs中快速筛选出具有生物化学显著性意义的候选活性化合物;目前有超高通量筛选(uHTS)、与细胞生物学相关联的HCS(高内涵筛选)和基于特定靶标的虚拟高通量筛选(VHTS)等。
为了避免已知(或undesirable)化合物的重复发现,HTS所鉴定生物活性化合物需经串联分析技术(eg. LC-NMR或HPLC-ESI-MS等)快速检测并结合高质量化学数据库进行搜索验证。

另外,有一种用于提高HTS药物筛选中化学数据库搜索效率和准确度的方法“ChemGPS”即预先给定一个“chemical space”(即化学空间,PS: 一个特定结构的结合空腔,类似于固相萃取SPE键合模板分子),从而用于候选化合物性能的提前评估筛选或虚拟去重复(virtual dereplication)。
2、分离检测技术
如前所述,“Dereplication”主要依赖于分析检测和数据库搜索技术,以达到在药物发现尽可能早的阶段就识别活性化合物的目的!文章中介绍的单一分离、检测技术手段均比较常规化,而联用技术(Hyphenated techiques)则极大可能地实现了对先导化合物快速的分离和检测。
在“Dereplication”早期阶段,也是目前实验室应用最为广泛的分LC-MS技术结合相应MS数据库,能快速提供大量结构信息,从而实现对感兴趣NPs进行有目的性地快速、有效分离。同时,LC-MS或LC-NMR等技术结合柱后生物活性自动测试(post-chromatographic bioautographic testing,即LC/bioassays),可实现活性LC-peak快速定位。

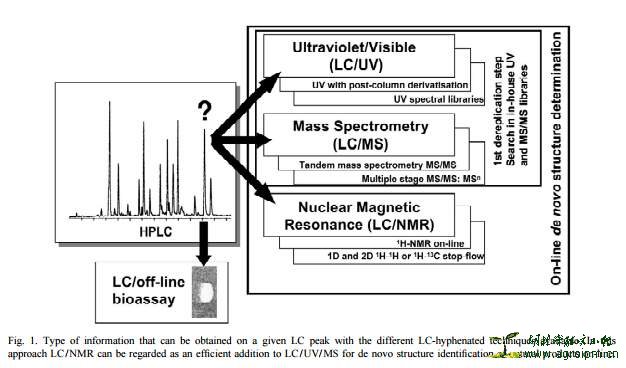
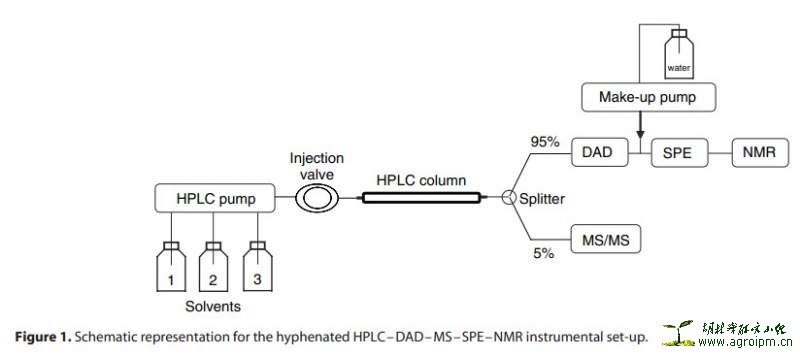
HPLC-DAD-MS-SPE-NMR技术:样品经最初的HPLC检测分离,某段色谱峰馏分的一小部分溶液送至MS,而其他剩余样品液则储存于SPE柱中;若MS分析显示该色谱峰馏分是感兴趣的NPs化合物,则用氘代溶剂将样品从SPE柱洗脱下来并送至NMR样品管进行结构鉴定分析,从而实现天然产物分离过程中的“Dereplication”。

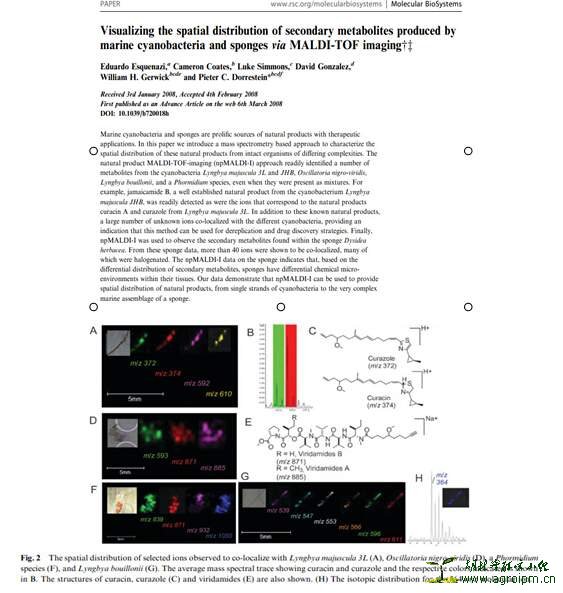
MALDI-TOF-imaging技术:可以描绘出完整有机体内NPs的特征性空间分布,不仅可鉴定出已知的NPs,而且还能对不同基质中未知离子峰化合物进行同步定位,是应用于天然药物发现“Dereplication”一种很不错的技术手段。
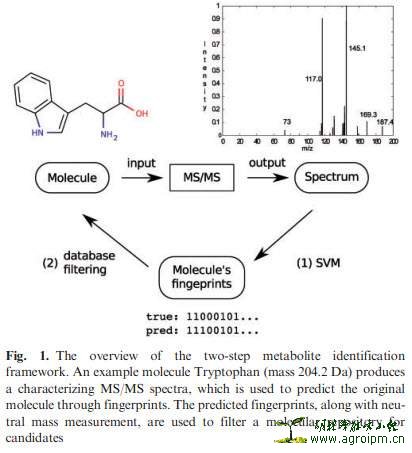
3、计算质谱光谱技术(Computational MS Spectrometry Tools) — 基于配体小分子(或其子结构)光谱数据搜索的“Dereplication”
从质谱MS数据来推断小分子化合物的结构,仍面临很大的挑战;采用质谱的方法来完成NPs“Dereplication”过程,最普遍的就是在数据库中进行碎片离子光谱数据的相似性搜索,从而获得已知化合物的准确结构或未知新化合物的局部最佳匹配结构。然而,目前无论是开放性的亦或是商业性的可获取MS-MS数据库规模都比较小,因此MS光谱数据搜索会经常失败。文章从这一问题出发,引出采用计算的方法对小分子化合物的碎片和其相对丰度进行精确预测的观点,从而使实体光谱数据库搜索转变为虚拟MS光谱数据库搜索!现有报道的计算方法有MetFrag、MetFusion、FT-BLAST、ISIS和FingerID五种,其中ISIS与FingerID是基于一定规则的(rule-based)虚拟碎片光谱数据计算方法。
现以FingerID(或fingerprint)为例,该方法是将未知化合物的提问光谱转变成为矢量特征信号,传送至碎片离子结构分类器(substructure classifier),再以相同的方式对未知化合物的指纹谱图fingerprint进行预测,从而获知其结构信息。

4、X-单晶衍射技术(X-ray crystallography)
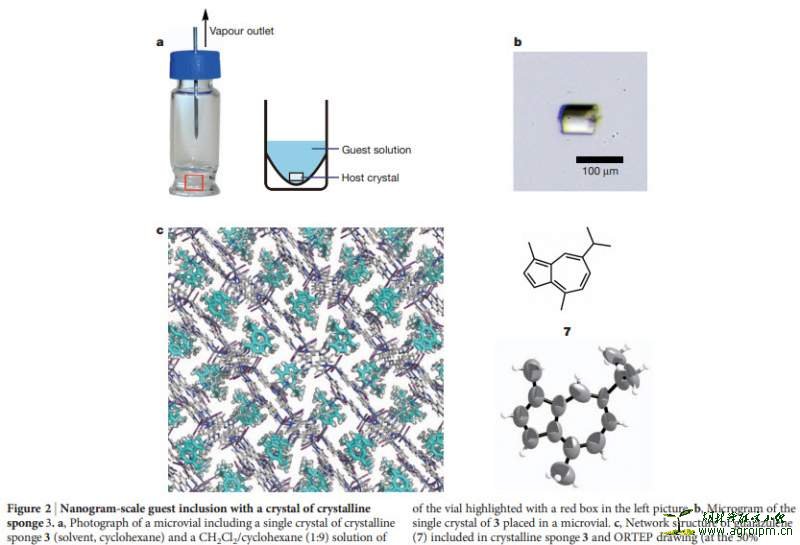
众所周知,X-单晶衍射可用于化合物分子结构和立体绝对构型的确定;同时,它也被很多研究者用于检测药物与靶蛋白的相互作用方式及其结构修饰。但该技术有一个极为显著的缺陷,即检测样品必须是单晶态;关于晶体的培养,算了,还是不说了,反正很多时候极为痛苦!
2013年Fujita及其合作者所研创的X-ray protocol for single-crystal diffraction (SCD) 分析新方法给我们带来了福音,它不需要你把样品培养成晶体;该方法仅仅需要你将少量特定的多孔复合物晶体丢到样品溶液中,它会对样品分子产生吸附,然后即可用于检测!目前该技术与HPLC相结合(LC-SCD),用于复杂多样性样品馏分的直接鉴定;毫无疑问,该技术的出现,开创了天然药物发现领域结构鉴定的新时代!

5、NMR新技术
天然产物领域NMR应用极为广泛,在这里仅介绍三方面的内容:
(1)The quantitative 1H-NMR (qHNMR)技术:
主要应用于活性天然产物的定量分析,其在NPs“Dereplication”过程中有两方面的意思:一方面为基于qHNMR的纯度-生物活性相关性检测,即qHNMR-based purity-activity relationships (PARs),也就是采用非色谱分离的方法识别单一化合物与其复杂天然基质潜在的相互作用机制;另一方面,是作为除了基于HPLC的天然产物定量分析之外的其他一种可选择性工具。

(2)The universal data-base (UDB) 构型分析
首先,我们采用NOE技术推测环系化合物的相对构型是比较普遍的,而对于非环系化合物NOE分析方法则无能为力了;针对非环系化合物相对构型的鉴定,文章综述了两种方法,即基于耦合常数J的Murata's分析法和基于universal data的UDB分析法。其中UDB相对构型分析方法,是Kishi等人在发现不同对应异构体1H NMR和13C NMR化学位移不同的基础上提出的。


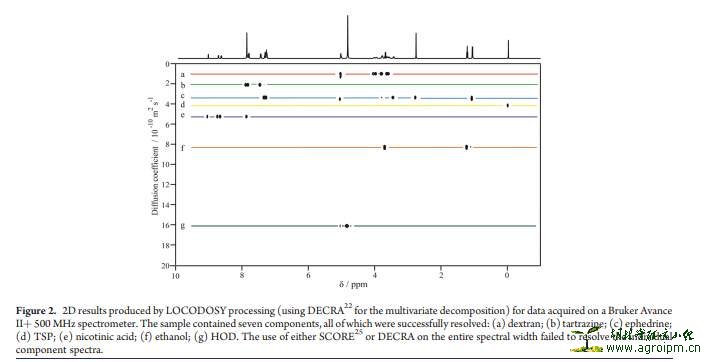
(3)Diffusion-ordered spectroscopy (DOSY)技术
在这里暂且译为扩散-序列光谱技术,该方法可根据在混合物中所给定有机化合物的扩散率而归属其信号;因为是混合物,所以其主要的缺陷就在于信号的重叠。有鉴于此,经多方面的长期努力,LOCO-DOSY技术的出现很好的解决了这一问题,该技术方法允许混合物中存在大量的不同化合物,且谱图分辨率较好。

6、计算机辅助结构解析 (CASE)
正如文中所述,计算机辅助结构解析是一个极为复杂的过程,针对一个未知的化合物,它需要强大的数据库和任何有助于结构推演的谱图信息。CAES的一般过程如下图所示:
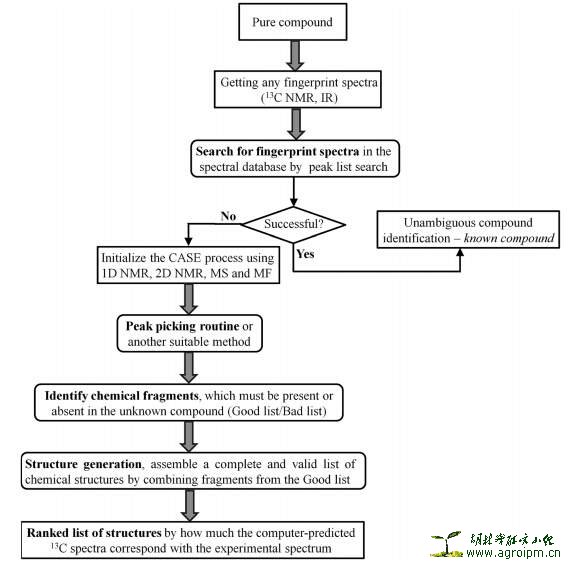
应用于天然产物“Dereplication”结构解析过程中的NMR数据库有 SpecInfo、CSearch、NMRShift DB和 ACD/Labs NMR等;而目前已报道的CAES软件系统有SESAMI、COCON、StrucEluc和SENECA等。其中,COCON系统的优势在于克服了常规CAES软件系统结构自动解析过程中的问题,从而实现较大分子化合物的结构解析。

而StrucEluc-2系统,则能够用2D-NMR数据阐明分子较大NPs的化学结构。

7、虚拟“dereplication”
其实,虚拟“dereplication”类似于计算机辅助药物设计,都是在解决这样的一个问题:如何找到具有特定生物活性的化合物;它也同样拥有基于配体的和基于靶标结构的两种“dereplication”方法。
在基于配体(ligand-based)的虚拟去重复化筛选过程中,应用最为广泛的主要是“定量构效关系模型”(即QSAR) 方法。Eg:

基于结构(structure-based)的虚拟去重复化筛选,首先必须经NMR、X-Ray crystallography或3D-建模的方法获得靶标蛋白的3D立体结构,然后以结合活性位点作为筛选条件,对大量的NPs进行虚拟筛选,从而去除没有结合活性的化合物。

8、组合技术(Combined techniques)
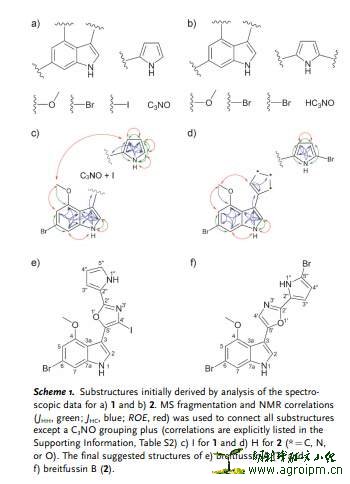
组合技术不仅是指不同分离检测技术的联用,也还包含了与不同方法学的结合,从而最大限度避免在毫无研究价值的样品上浪费时间和精力。Eg: 原子力场-显微技术(AFM)、CASE和密度泛函理论计算相结合,用于特殊骨架结构化合物 breitfussin A 20和B 21的发现:


在文章结尾部分Future Prospects中,作者提出了很多让人无限憧憬的观点,如构建类似于基因库的天然产物数据库“NPsDataBank”和 HPLC-DAD-BDC-MS-SPE-NMR-SCD联用技术等。最后,作者无限遐想地提出,在不久的将来我们能够拥有高精确度和灵敏度的NPs检测分析手段;更为久远的未来,在显微镜下,NPs会自动显现出自身的分子结构,而NPs结构的推测也将在亚细胞水平通过可视化的方式进行。







